05/12/2016
Khi nghe cụm từ này, bạn thường nghĩ tới một người máy thông minh có thể làm các thao tác như con người. Cụ thể hơn, nó có thể “learn,” tức học. Ví dụ, bạn dạy người máy tiếng Anh, và rồi sau đó nó có thể đọc. Bạn dạy nó âm nhạc, và nó có thể viết một bản nhạc mới. Nghe thật không tưởng. Một ngày nào đó, người máy sẽ học đủ nhiều, trở nên đủ thông minh để chiếm lĩnh thế giới. Loài người sẽ tuyệt chủng.
Có lẽ viễn cảnh này sẽ trở thành hiện thực. Nhưng cũng có lẽ bạn đã tưởng tượng quá nhiều sau khi xem “The Terminator”1. Nhưng bất kể viễn cảnh nào sẽ xảy ra chăng nữa, bạn cũng sẽ nghĩ tới machine learning (tạm dịch: máy học)2 như là một công nghệ siêu phức tạp với hàng triệu dòng mã được viết bởi ngôn ngữ ngoài hành tinh. Nhưng đừng cảm thấy ngại. Những thứ phức tạp thường được xây dựng dựa trên những điều giản đơn. Machine learning cũng vậy. Bạn sẽ ngạc nhiên khi biết rằng công nghệ machine learning cao siêu này thực ra cũng chỉ đến từ những kiến thức toán căn bản bạn học hồi phổ thông mà thôi.
Trước khi ta đi vào chi tiết, ta cần định nghĩa lại từ ngữ. Ta đều biết “learning” là gì. Nhưng để thực sự hiểu từ “learning” trong “machine learning,” ta cần “hạ chuẩn” từ này xuống một tí. Thường thì từ “learning” gắn liền với việc thu thập thêm kiến thức mới. Khi ta học một khái niệm hay cơ chế mới, ta cố gắng hiểu chúng bằng suy luận logic hoặc tưởng tượng trực quan. Những khái niệm và cơ chế này trở thành kiến thức của chúng ta. Đó là một nghĩa “cấp cao” của từ “learning.” Có một nghĩa khác, cấp “thấp” hơn. Hãy nghĩ tới “learning” như việc phán đoán dựa trên kinh nghiệm quá khứ. Ví dụ, khi ta đi bộ trên đường, ta vấp phải một hòn đá và ngã xuống. Lần sau khi ta ra khỏi nhà, ta phán đoán rằng, nếu ta đi trên cùng con đường đó, ta sẽ gặp lại hòn đá, và nếu không tránh nó ra, ta sẽ lại vấp ngã. Đó là “learning.” Học nghĩa là phán đoán dựa trên quá khứ. Kinh nghiệm trong quá khứ (đi bộ trên đường, vấp phải hòn đá và ngã) nói với bạn rằng nếu bạn lặp lại những bước tương tự (đi trên cùng con đường đó, và vấp phải hòn đá) thì bạn chắc chắn sẽ gặp đúng một kết quả (ngã). Để cho đơn giản, ta nên nghĩ tới từ “learning” theo nghĩa hẹp này. Việc bạn làm gì với dự đoán này (ví dụ như chọn đường khác để đi, hay né hòn đá ra) là một câu chuyện khác.
Đó là “learning.” Phán đoán dựa trên kinh nghiệm quá khứ. Nghe thật đơn giản. Nhưng con người thì phức tạp, và cách ta phán đoán thường không rõ ràng chút nào. Làm sao mà máy có thể “learn,” có thể phán đoán như người được? Giờ là lúc để “hạ chuẩn” thêm một lần nữa. Lần này, ta sẽ hạ chuẩn từ “kinh nghiệm.” Kinh nghiệm của con người bao gồm nhiều thứ. Những thứ này có thể là mùi, hình ảnh, cảm xúc… và những đặc tính khác. Kinh nghiệm đóng vai trò như “input,” một dạng thông tin đầu vào, đối với chúng ta. Con người xử lý “input” (kinh nghiệm quá khứ) để cho ra “output” (phán đoán). Nếu chúng ta thay “người” bằng “máy,” thì câu hỏi được đặt ra bây giờ là, “máy tính thì trải nghiệm gì?” Hiển nhiên, nó không thể trải nghiệm những đặc tính định tính như trực giác hay cảm xúc được. Thay đổi từ ngữ một chút, ta có một câu hỏi tương đương là, “Input của máy tính là gì?” Giờ thì ta có thể trả lời: “input” của máy tính là những con số. Máy tính xử lí dữ liệu được mã hoá dưới dạng rất nhiều con số. Machine learning nghĩa là máy tính xử lí những con số đã có để đưa ra phán đoán. Tới đây bạn sẽ hỏi tiếp, “vậy phán đoán dạng gì?” “input” như thế nào thì sẽ cho ra “output” như thế. Trong machine learning, một chiếc máy tính xử lí những con số để cho ra những con số khác.
Giải thích ở trên vẫn còn trừu tượng lắm. Lấy một ví dụ cụ thể. Giả sử bạn đi vòng quanh trong khu phố và thu thập thông tin về nhà cửa. Bạn thu thập 2 số liệu cho mỗi căn nhà: giá và diện tích. Giả sử bạn hỏi 500 hộ dân trong khu. Vậy là bảng dữ liệu của bạn có hai cột, diện tích và giá, cùng với 500 dòng, tương ứng với 500 căn nhà. Trong thuật ngữ “machine learning,” diện tích căn nhà được gọi là một “feature” (tạm dịch: đặc điểm), và 500 là số lượng “training examples” (tạm dịch: dữ liệu mẫu). Nhiệm vụ của chuyên gia machine learning là bảo máy tính xử lí bảng dữ liệu 500 dòng và 2 cột này. Giả sử có căn nhà thứ 501 trong khu đang được xây, và bạn muốn biết giá trị của nó. Bạn lấy diện tích căn nhà 501 này, cho vào máy tính, và máy tính sẽ xuất ra cho bạn một con số chính là giá của căn nhà đó. Đó là machine learning. Máy tính xử lí những con số để cho ra những con số khác.
Nếu bạn hỏi một chuyên gia nhà đất làm thế nào để định giá một căn nhà, thì cô ấy có thể cho bạn một danh sách dài “features” chứ không chỉ có diện tích. Cô ấy sẽ muốn biết địa điểm (căn nhà có ở trong khu nhà ở cao cấp hay không?), vật liệu xây dựng, số lượng phòng… Để cụ thể hơn, ta có thể “toán hoá” phán đoán của máy tính bằng phương trình:
hθ(x) = x0 + θ1x1 + θ2x2 + θ3x3 + θ4x4
- x1: diện tích nhà (mét vuông)
- x2: địa điểm (=1 nếu nhà ở trong khu an toàn, gần trung tâm, và =0 nếu nhà ở xa trung tâm và ở trong khu vực không an toàn)
- x3: material (=1 nếu nhà xây bằng vật liệu tốt, và =0 nếu dùng vật liệu dởm)
- x4: số lượng phòng
- hθ(x): phán đoán của máy tính dựa trên (các) thông số x
- θ (theta): có thể tạm hiểu theta như là một bộ giá trị gồm 4 giá trị cụ thể tương ứng với θ1, θ2, θ3, θ4. Ví dụ: {1, 2, 3, 4} hay là {0.5, 0.5, 1, 3} hay là {9, 1.2, 6, -0.5}. Kí hiệu hθ ý chỉ “phán đoán với một bộ giá trị theta cụ thể”. (Có thể nhiều hoặc ít hơn, tuỳ thuộc vào số lượng “features;” ở trong ví dụ này ta có 4 “features.”)
Tạm thời, bạn có thể bỏ qua x0. (x0 là phán đoán của máy khi các “features” khác bằng không. Thật vậy, khi x1=x2=x3=x4=0 thì hθ(x) = x0) Trong ví dụ của chúng ta, diện tích một căn nhà bằng 0 là điều vô lí, nên ta không cần quan tâm lắm đến x0 ở đây.
Ta sắp xếp dữ liệu vào hàng và cột. Mỗi hàng chứa thông tin của một căn nhà. Mỗi hàng có 5 ô (tương ứng 5 cột), mỗi cột chứa giá trị của một “feature” (diện tích, vị trí, vật liệu, và số phòng). Hai cột vị trí và vật liệu chỉ chấp nhận 2 giá trị định lượng đại diện: 1 với địa điểm đẹp/vật liệu tốt và 0 đối với địa điểm xấu/vật liệu xoàng.
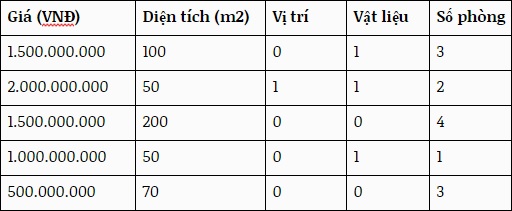
Bảng trên phản ánh thực tế: căn nhà này, với diện tích, vị trí, vật liệu và số phòng như thế này, đã được bán với giá này. Bảng trên là “kinh nghiệm quá khứ” đối với máy tính. Câu hỏi bây giờ là, làm thế nào để máy tính xử lí “kinh nghiệm quá khứ” này để phán đoán giá một căn nhà mới? Giả sử bạn có một căn nhà 80 mét vuông, ở một vị trí đẹp, với vật liệu tầm thường, và 4 phòng ngủ. Nếu bạn bán nhà, căn nhà sẽ được mua với giá bao nhiêu?
Nếu bạn để ý, ta đã có x1, x2, x3 và x4. Để tính h(X), với X={x1, x2, x3 và x4} (tức là phán đoán của máy tính về giá nhà), chúng ta cần theta1, theta2, theta3 và theta4 (θ1, θ2, θ3, và θ4). Đây là lúc quá trình “machine learning” bắt đầu. Mục tiêu là phán đoán càng chính xác càng tốt. Nói cách khác, chúng ta muốn y – h(x) = 0 (y là giá nhà thực sự khi bán, h(x) là phán đoán giá bán nhà của máy tính). Nhưng điều này trông khó khăn. Thay vì nhắm tới mục tiêu y và h(x) bằng nhau, ta có thể nhắm tới việc làm sao mà khoảng cách giữa y và h(x) nhỏ nhất. Nghĩa là, ta muốn tối thiểu hoá (minimize) giá trị (y – h(x))^2. (Tại sao lại phải bình phương? Vì nếu không bình phương thì ta có thể sẽ có một số âm. Số âm thì không có số nào nhỏ nhất, nên việc “minimize” là vô nghĩa.) Để cho tiện, ta sẽ gọi (y – h(x))^2 là “cost.” Cost nhỏ nhất khi bằng 0, tức là trong trường hợp lí tưởng: y = h(x), phán đoán của máy chính xác hoàn toàn.
Máy tính sẽ thử nhiều bộ giá trị theta với các giá trị {theta1, theta2, theta3, theta4} khác nhau cho đến khi cost nhỏ nhất. Khi đã có một bộ giá trị theta cụ thể mà ở đó cost nhỏ nhất, ta có thể phán đoán giá căn nhà của bạn, với sai lệch thấp nhất (nói cách khác, (y – h(x))^2 nhỏ nhất).
Để cho đơn giản thì giờ ta cho rằng chúng ta chỉ cần 2 theta là theta0 và theta1.
h(x) = theta0 + theta1*x
Tưởng tượng rằng bạn có một hệ trục 3 chiều. Chiều rộng là theta0. Chiều dài là theta1. Và chiều cao là “hàm cost”. Hàm cost là gì? Đừng vội. Bạn có nhớ rằng mục tiêu là tối thiểu hoá (y – h(x))^2? Vì chúng ta có nhiều dữ liệu (hay “training examples”), nên chúng ta phải tối thiểu hoá nhiều (y – h(x))^2. Hàm cost là tổng của tất cả các (y – h(x))^2 với mỗi (x,y) là một “training example” trong dữ liệu.
(y(1) – h(x(1)))^2 = (y(1) – (theta0 + theta1* x(1)))^2
(y(2) – h(x(2)))^2 = (y(2) – (theta0 + theta1* x(2)))^2
(y(3) – h(x(3)))^2 = (y(3) – (theta0 + theta1* x(3)))^2
…
(y(m) – h(x(m)))^2 = (y(m) – (theta0 + theta1* x(m)))^2
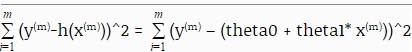
y(2) nghĩa là y của training example thứ 2 (hay nói cách khác, giá trị thực sự khi bán của căn nhà số 2). Nó không có nghĩa là y^2 (y bình phương). Ghi y(i) và x(i) là cách kí hiệu số thứ tự của “training example” (hay số thứ tự của một căn nhà trong dữ liệu) mà thôi. Khi ta cộng tất cả các “cost” lại với nhau (mỗi cost tương ứng với sự khác biệt giữa giá trị do máy tính phán đoán, và giá trị thực khi bán của một căn nhà), ta có hàm cost, hay còn được kí hiệu là J(theta). Theta nằm trong ngoặc có nghĩa là giá trị hàm cost phụ thuộc vào giá trị của theta (hay chính xác hơn, bộ giá trị theta, vì chúng ta có theta0 và theta1). Khi ta thay đổi bộ giá trị theta (tức thay đổi giá trị của theta0 hay/và giá trị của theta1), J cũng thay đổi theo. Bạn cứ nghĩ đồ thị 3 chiều của chúng ta như là một địa hình với núi đồi và thung lũng. Độ cao tại một điểm so với mặt đất là J. Kinh độ và vĩ độ của điểm đó là theta0 và theta1. Bạn có thể xác định độ cao của một điểm so với mặt đất (tức xác định được J) nếu bạn biết kinh độ và vĩ độ (theta0 và theta1). Giả sử có một dòng sông trên địa hình này, chảy từ nơi trên cao là đỉnh núi xuống một thung lũng và tạo thành một cái hồ. Bạn muốn biết chính xác toạ độ của đáy hồ này ở đâu vì chính ở toạ độ này, độ cao so với mặt đất là thấp nhất, tức tổng các bình phương (y – h(x))^2 là thấp nhất.
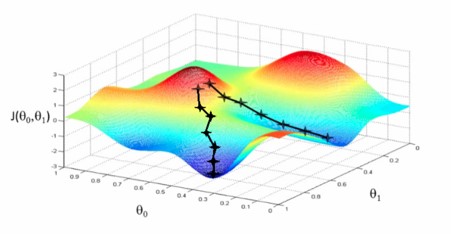
Nhiệm vụ của máy tính như là nhiệm vụ của dòng sông đen như trong hình trên, tức là thay đổi toạ độ liên tục (theta0 và theta1) cho đến khi nó không còn chảy đi đâu được nữa. Tưởng tượng một dòng sông chảy từ đỉnh núi cao (màu đỏ) đến đáy hồ (xanh). Hai dòng sông đen ý chỉ có 2 bộ giá trị theta mà ta có thể tìm được. Hai bộ này có thể sẽ không giống nhau, và có thể có bộ sẽ cho ra điểm thấp hơn bộ kia, nhưng đó là một vấn đề khác mà machine learning sẽ giải quyết, không nằm trong phạm vi bài viết này. Theo như thuật ngữ “Giải tích,” thì đây là 2 “cực tiểu địa phương” (local minima).
Nói ngắn gọn:
- Bạn nhập vào những con số (diện tích nhà, giá nhà)
- Máy tính sẽ ngẫu nhiên tạo ra những thông số (theta), phán đoán dựa trên những thông số này, và tính toán sự khác biệt giữa những con số bạn nhập vào (y, giá nhà thực sự) và những con số do máy tính tạo ra (h(x), giá nhà do máy tính đoán).
- Máy tính sẽ thay đổi các thông số (theta) để sự khác biệt, tức (y – h(x))^2, nhỏ nhất có thể.
- Từ đó, máy tính tìm ra được thông số tốt nhất để phán đoán giá một căn nhà mới.
Giờ bạn sẽ hỏi: máy tính thay đổi giá trị theta như thế nào? Ngẫu nhiên chọn một bộ số, rồi tăng mỗi giá trị trong bộ số đó lên 1 đơn vị hay sao? Câu trả lời: có nhiều cách để thay đổi giá trị theta. Mỗi cách được gọi là một “thuật toán machine learning” (machine learning algorithm). Những thuật toán thông dụng nhất là “Gradient Descent” và “Neural Networks.” Việc giải thích những thuật toán này cần những kiến thức về lập trình và toán (nhất là đại số tuyến tính), mà sẽ vượt ra khỏi phạm vi bài viết này. Nếu bạn có hứng thú, có thể tìm học lớp “Machine Learning” của giáo sư Andrew Ng trên trang Coursera.org.
Tóm lại, “learning” là đưa ra những phán đoán dựa trên kinh nghiệm quá khứ. Và đối với “machine,” kinh nghiệm quá khứ và phán đoán đều là những con số. Vậy, machine learning là dùng máy tính thử các giá trị theta khác nhau để tìm một phương trình h(x) = theta*x sao cho tổng các giá trị của (y(n)-h(x(n)))^2 nhỏ nhất. Dĩ nhiên, machine learning không chỉ được ứng dụng trong phán đoán giá nhà. Công cụ này có thể còn được dùng để tính toán xem đầu tư vào đâu sẽ có lợi nhất, gợi ý cho bạn những món đồ bạn sẽ thích (khi bạn mua sắm online trên Amazon.com hay Tiki.vn chẳng hạn), bộ phim hay bài hát bạn sẽ thích (như trên Netflix, Spotify). Ngoài ra, machine learning còn được dùng để nhận dạng kí tự viết tay, và gần đây nhất là để làm xe tự vận hành. Vào ngày 25/10/2016, Uber vừa cho chạy thử một chiếc công-ten-nơ tự vận hành chuyển bia Budweiser từ Fort Colins đến Colorado Springs (hơn 190km đường cao tốc) ở tiểu bang Colorado, Hoa Kì. Con người sẽ ngày càng đưa ra những phán đoán chính xác hơn nhờ máy tính, và vì máy tính có thể học hỏi, máy tính sẽ làm hết phần lớn những công việc của con người. Trong tương lai, nhờ machine learning, nhiều thao tác cần tư duy cơ bản sẽ do máy đảm nhiệm, ví dụ như nấu ăn, hay xử lí giấy tờ hành chính. Đến lúc đó, việc của con người sẽ là tập trung vào những thứ cần khả năng tư duy cao, như nghiên cứu khoa học và tạo ra thuật toán máy tính mới.
The Terminator (hay còn biết đến với tên gọi “Kẻ Huỷ Diệt” ở Việt Nam) là series phim khoa học viễn tưởng của Mỹ do nam diễn viên Arnold Schwarzenegger thủ vai chính. Vào thế kỉ 21, loài người mở cuộc chiến chống lại người máy thông minh vốn đang thống trị toàn cầu. Một chiến binh người máy gọi là “The Terminator” được gửi về quá khứ để ám sát một phụ nữ, người sẽ sinh ra vị cứu tinh của nhân loại trong tương lai.↩
Trí tuệ nhân tạo (Artificial Intelligence – AI) là một ngành nhỏ thuộc Machine Learning.↩